






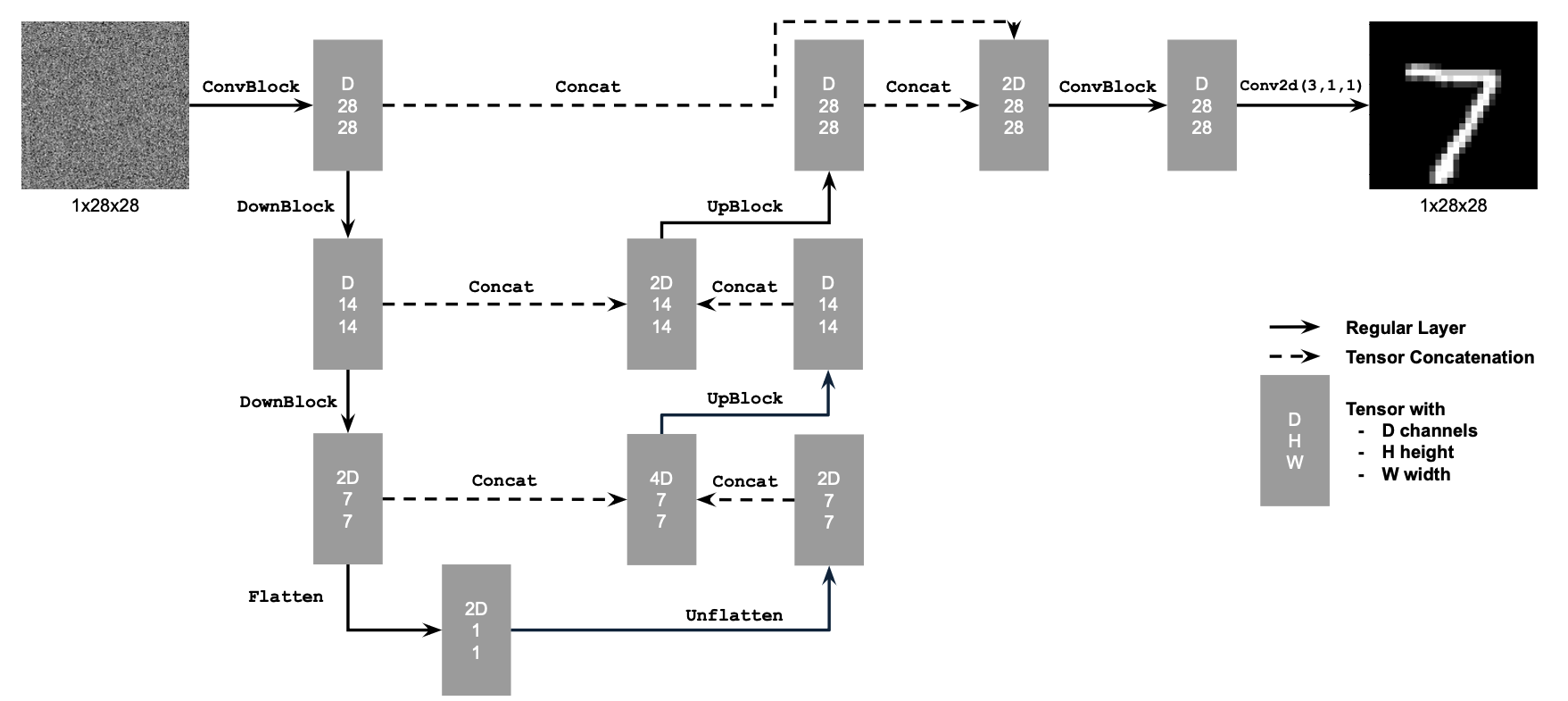
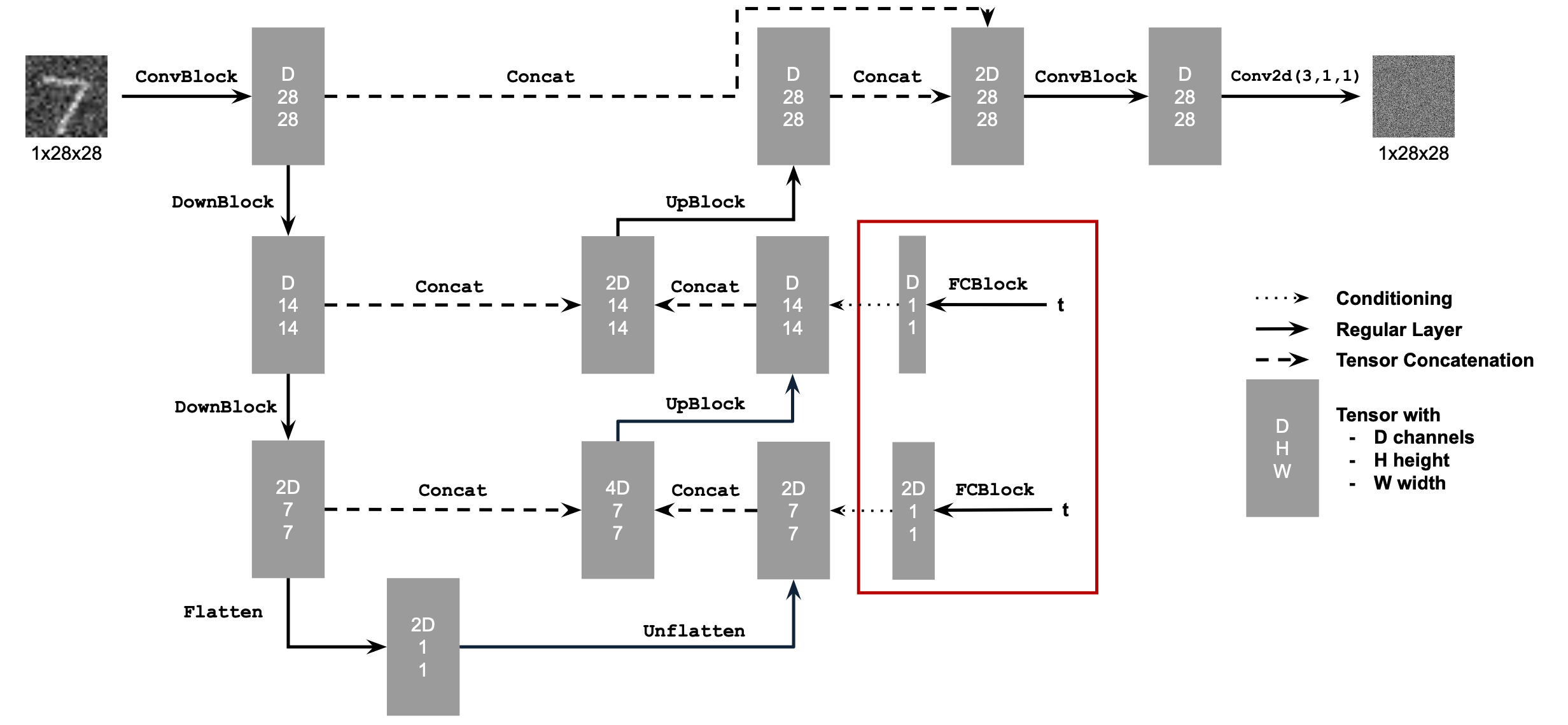
Campanile

t=250

t=500

t=750
Noisy t=250
Noisy t=500
Noisy t=750

Denoised t=250

Denoised t=500

Denoised t=750
Noisy t=250
Noisy t=500
Noisy t=750

Denoised t=250

Denoised t=500

Denoised t=750

Noisy t=690

Noisy t=540

Noisy t=390

Noisy t=240

Noisy t=90

Noisy t=690

Gauss

One-Step

Iterative

Sample 1

Sample 2

Sample 3

Sample 4

Sample 5

Sample 1 (CFG)

Sample 2 (CFG)

Sample 3 (CFG)

Sample 4 (CFG)

Sample 5 (CFG)

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20
Campanile

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

Berkeley

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

Chinatown

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

brainrot

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

circle Kenny

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

golden state

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

wallpaper
Campanile

Mask

To Replace






Shuttle

Mask

To Replace






Berkeley

Mask

To Replace






i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

i_start=1

i_start=3

i_start=5

i_start=7

i_start=10

i_start=20

'an oil painting of an old man' + 'an oil painting of people around a campfire'

'an oil painting of a snowy mountain village' + 'an oil painting of people around a campfire'






'a lithograph of a skull' + 'a lithograph of waterfalls'

'an oil painting of an old man' + 'a photo of the amalfi coast'

'a photo of a man' + 'a photo of the amalfi coast'

Noising with sigma=0.0, 0.2, 0.4, 0.6, 0.8

Denoising results for sigma = 0.0, 0.2, 0.4, 0.6, 0.8, 1.0


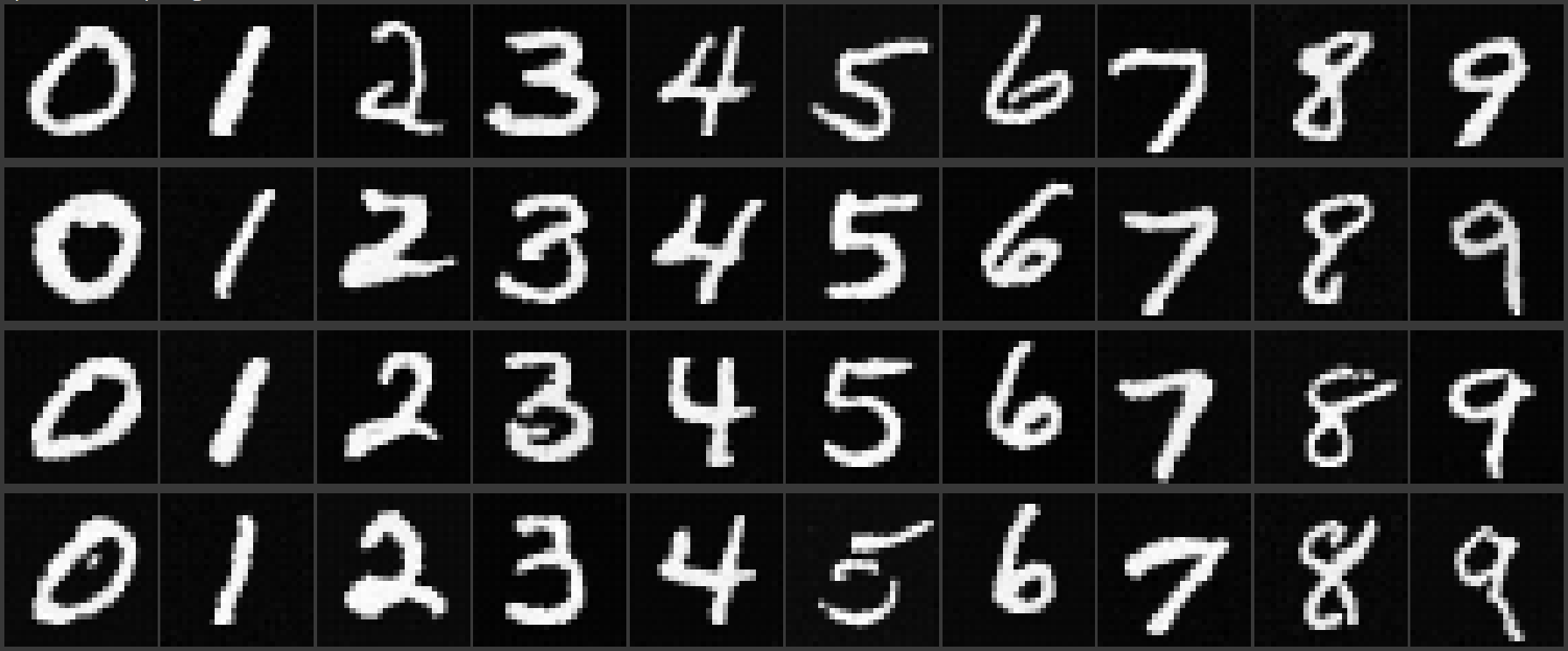
Epoch 1

Epoch 5

Epoch 10

Epoch 15

Epoch 20



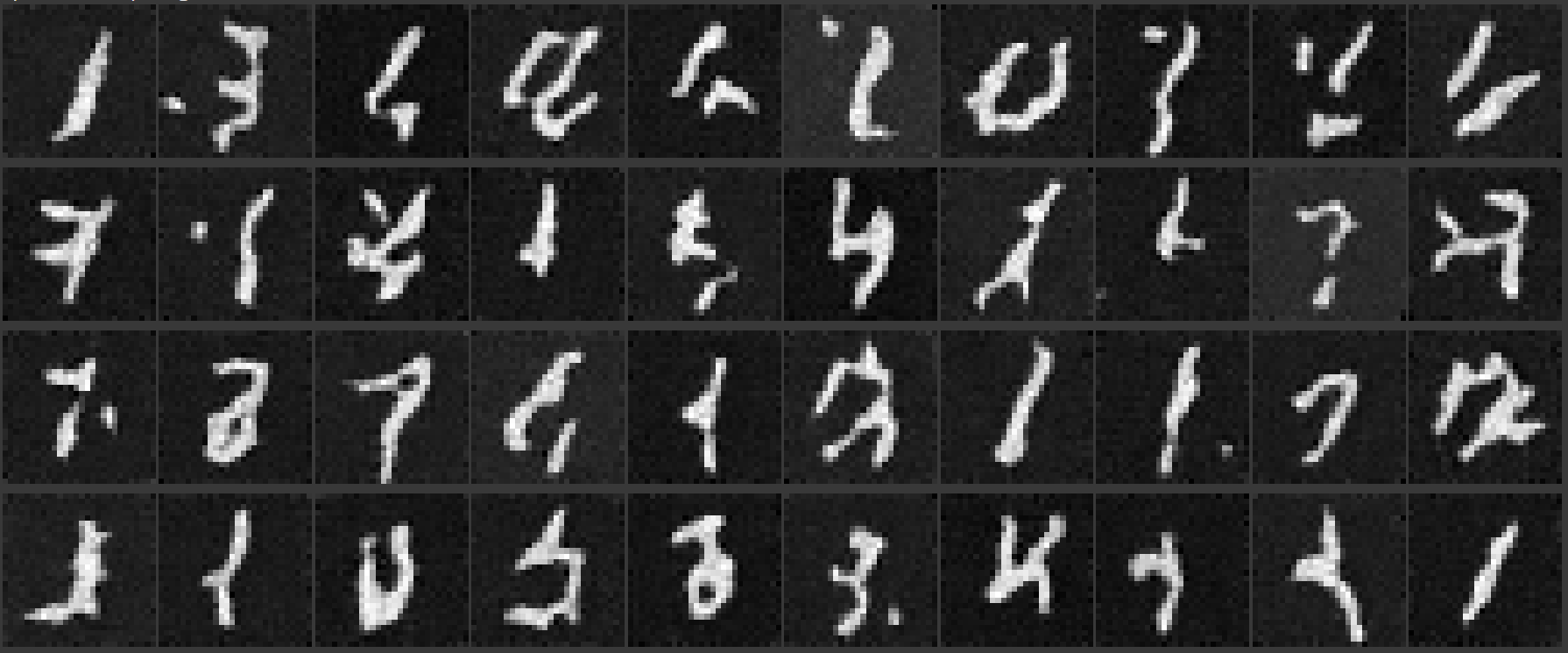
Epoch 1

Epoch 5

Epoch 10

Epoch 15
Epoch 20
Acknowledgements |